I’m also interested in implementing Hierarchical Dirichlet Process models in Edward. I’m starting with Gaussian DPMM. I tried the example mentioned here, however, I get means that are very close to zero and the posterior predictive is concentrated near zero.
I went back to the unsupervised learning tutorial and added stick-breaking. It uses ParamMixture class and Gibbs sampling. Here’s the complete code:
import numpy as np
import pandas as pd
import edward as ed
import tensorflow as tf
import seaborn as sns
import matplotlib.cm as cm
import matplotlib.pyplot as plt
from scipy.stats import mode
from edward.models import Gamma, Beta
from edward.models import Categorical, Dirichlet, Empirical, Normal
from edward.models import InverseGamma, MultivariateNormalDiag, ParamMixture
def generate_data(N):
pi = np.array([0.4, 0.6])
mus = [[1,1], [-1,-1]]
stds = [[0.1,0.1],[0.1,0.1]]
x = np.zeros((N,2), dtype=np.float32)
for n in range(N):
k = np.argmax(np.random.multinomial(1, pi))
x[n,:] = np.random.multivariate_normal(mus[k], np.diag(stds[k]))
return x
ed.set_seed(0)
N=500 #number of data points
K=8 #number of components
D=2 #dimension
x_train = generate_data(N)
with tf.name_scope("model"):
alpha = Gamma(concentration=1.0, rate=1.0, name='alpha')
beta = Beta(concentration1=1.0, concentration0=tf.ones(K)*alpha)
pi = tf.concat([tf.reshape(beta[0],[1]), tf.reshape(tf.multiply(beta[1:],tf.cumprod(1 - beta[:-1])), [K-1])], 0)
mu = Normal(loc=tf.zeros(D), scale=tf.ones(D), sample_shape=K)
sigmasq = InverseGamma(concentration=tf.ones(D), rate=tf.ones(D), sample_shape=K)
x = ParamMixture(pi, {'loc': mu, 'scale_diag': tf.sqrt(sigmasq)},
MultivariateNormalDiag, sample_shape=N)
z = x.cat
with tf.name_scope("posterior"):
T = 1000 #number of MCMC samples
qmu = Empirical(tf.Variable(tf.zeros([T,K,D])))
qsigmasq = Empirical(tf.Variable(tf.ones([T,K,D])))
qz = Empirical(tf.Variable(tf.zeros([T,N], dtype=tf.int32)))
with tf.name_scope("inference"):
inference = ed.Gibbs({mu: qmu, sigmasq: qsigmasq, z: qz},
data={x: x_train})
inference.initialize()
sess = ed.get_session()
tf.global_variables_initializer().run()
t_ph = tf.placeholder(tf.int32, [])
running_cluster_means = tf.reduce_mean(qmu.params[:t_ph], 0)
for i in range(inference.n_iter):
info_dict = inference.update()
inference.print_progress(info_dict)
t = info_dict['t']
if t % inference.n_print == 0:
print "\ninferred cluster means: "
print sess.run(running_cluster_means, {t_ph: t-1})
#end if
#end for
print "computing cluster assignments..."
#compute likelihood for each data point averaged over many posterior samples
#x_post has shape (N, 100, K, D)
post_num_samples = 500
mu_sample = qmu.sample(post_num_samples)
sigmasq_sample = qsigmasq.sample(post_num_samples)
x_post = Normal(loc=tf.ones([N, 1, 1, 1]) * mu_sample,
scale=tf.ones([N, 1, 1, 1]) * tf.sqrt(sigmasq_sample))
x_broadcasted = tf.tile(tf.reshape(x_train, [N, 1, 1, D]), [1, post_num_samples, K, 1])
#sum over latent dimension, then average over posterior samples
#log_liks final shape is (N, K)
log_liks = x_post.log_prob(x_broadcasted)
log_liks = tf.reduce_mean(log_liks, 3)
log_liks = tf.reduce_mean(log_liks, 1)
#choose cluster with the highest likelihood
assignments = tf.argmax(log_liks, 1).eval()
#thin = 2
#burnin = 100
#qz_trace = qz.params[burnin::thin].eval()
#assignments, _ = mode(qz_trace, axis=0)
#assignments = qz.mean().eval()
pi_dist, _ = np.histogram(assignments, bins=range(K+1))
pi_dist = pi_dist/np.sum(pi_dist, dtype=np.float32)
#compute posterior means
#qmu_mean = qmu.mean().eval()
qmu_mean_samples = tf.stack([qmu.sample() for _ in range(post_num_samples)])
qmu_mean_samples_avg = np.mean(qmu_mean_samples.eval(), axis=0)
#posterior predictive check
print "posterior predictive check..."
#x_post_samples = tf.reduce_mean(x_post, 2)
#x_post_samples = tf.reduce_mean(x_post_samples, 1)
#x_post_samples_avg = x_post_samples.eval()
x_post2 = ed.copy(x, {mu: qmu, sigmasq: qsigmasq, z: qz})
x_post2_samples = tf.stack([x_post2.sample() for _ in range(post_num_samples)])
x_post2_samples_avg = x_post2_samples.eval()
#generate plots
plt.figure()
plt.scatter(x_train[:,0], x_train[:,1], c=assignments, cmap=cm.bwr)
plt.axis([-3, 3, -3, 3])
plt.title('DP cluster assignments')
plt.xlabel("X1")
plt.ylabel("X2")
plt.grid()
plt.savefig('./figures/gaussian_dpmm_mixture.png')
plt.figure()
plt.scatter(x_post2_samples_avg[:,0], x_post2_samples_avg[:,1])
plt.scatter(qmu_mean_samples_avg[:,0], qmu_mean_samples_avg[:,1], s=50, marker='x', color='r')
#plt.axis([-3, 3, -3, 3])
plt.title("Posterior Predictive Check")
plt.xlabel("X1")
plt.ylabel("X2")
plt.grid()
plt.savefig('./figures/gaussian_dpmm_ppc.png')
plt.figure()
plt.bar(range(K), pi_dist, color='r', label='pi_k')
plt.title('mixture proportions')
plt.xlabel('clusters')
plt.ylabel('proportions')
plt.legend()
plt.savefig('./figures/gaussian_dpmm_mixture_proportions.png')
And the resulting figures:
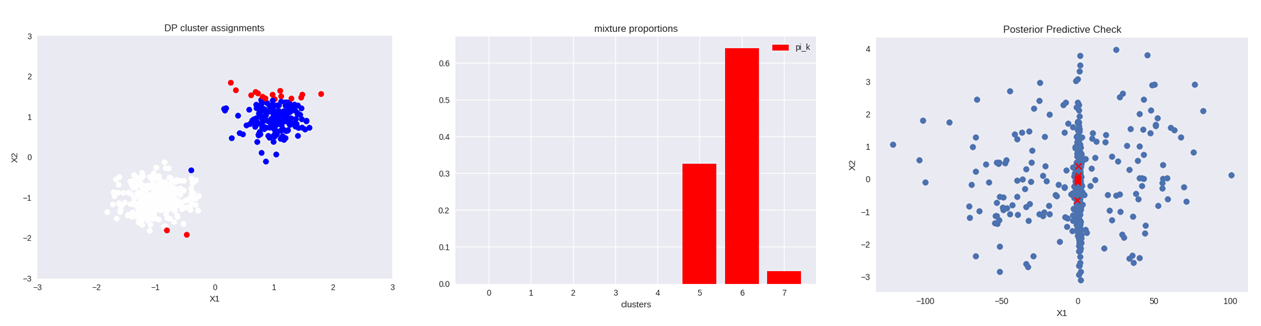
The assignments (left plot) somewhat make sense. Although there are multiple ways of computing the assignments: based on log_prob of posterior (used in this code as well as the tutorial), samples of the mean of qz (will give different results) and mode of qz trace after some burn in. Not sure which is the best way of computing the assignments. The mixture proportions (middle plot) is a normalized histogram of assignments, that basically indicates that out of K=8 initial clusters the maximum log_prob was assigned to only three. Finally, the posterior predictive check (right plot) shows data generated from the posterior mixture model. I would expect it to look close to the original data (left plot).
I appreciate any comments and suggestions on computing the assignments, posterior predictive check or perhaps using a different inference algorithm or mixture model class. Are there any ways in which the code could be improved?
